#10 System Design: Asynchronous Processing

Backend Developer and a busy mom who loves technology and sharing knowledge that makes her fulfilling and happy
Welcome to the 10th episode :) Thanks to Hashnode for featuring the previous article "Sharding" :)
Before we dive in, Do you like Subway Sandwiches? or Pizzas?

I do like both very much :)
Synchronous Processing
Before talking about asynchronous processing its important to understand what synchronous processing is. Let's now assume, you're ordering a subway sandwich, the server assembles the sandwich based on your inputs in real time according to the sequence of bread, cheese, toppings, sauce etc. This is exactly synchronous processing, i.e you get to see what was added to your sandwich after every input that you gave.
In the same pattern, if you submitted a request to a API it would return you a response 200(OK) immediately this is synchronous processing
Asynchronous Processing

This is similar to ordering a "Carryout" pizza from Dominoes, you choose what pizza crust, sauce and the toppings and place the order online so that you can pickit up when they text you saying that your is ready.
This is exactly what happens in asynchronous processing....
If you compare the above process of ordering from Subway Vs Dominoes
You literally had to be present to give inputs to the server during the preparation of sandwich, whereas when you ordered pizza you simply specified what you wanted and went to do your routines, while the pizza was being prepared and once it was done, you got the response :) oops.. the pizza..
So if I'm super hungry while I was out, and that I couldn't wait, I will then choose to go have a Sub Vs I'm shopping around and placed an order for pizza so I can pick up when its ready ! is all about Sync Vs Async Processing
Why does it matter?
We can't do all the work in a synchronous way while making the user sit and watch as we did the process. Well the sub max takes couple of mins.
What if it was some process that required X mins or hours to finish. Do you want to make the user sit for a response until then? if it's the case that's a awful experience I would say and is not going to be relied upon by the users.
Google can't explore the web in real time for every search, and YouTube can't handle all of the videos that are being posted at the same time. At some point, a system will become unreliable due to a lack of capacity or because the task will take too long.
Different Flavors of Asynchronous Processing
1. Batch Processing
Typically used in applications that process huge amounts of data on a regular basis for periodic evaluation.Batch processing would be ideal for corporate finance and accounting applications.
Batch processing is used to process data in batches and it reads data input, processes it, and writes it to the output. Apache Hadoop is the most well-known and popular open source implementation of batch processing and a distributed system using the MapReduce paradigm.
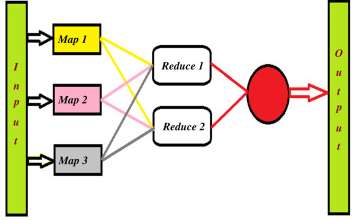
MapReduce work well in situations where running in parallel helps speed up the task.
For example, if you have a complex analytics task where running on one machine would take days or weeks, splitting it across many processes makes it faster. Google uses it to process and index many different web pages in parallel. Notice, that MapReduce won't work as well for data that's not repetitive, as it won't condense down (reduce) as much.
2. Streams
There are lot of devices in our daily lives emitting data eg Apple watch, door bells you get the idea !!! IoT devices are everywhere
There are lot of events that are happening on these devices, when you click something on your apple watch to check weather or events happening on a trading platform. These click stream data, sensor data is used to build dashboards, generate metrics and can even deliver data to data lakes for generating real-time-insights where accuracy is critical.
However, complexity and fragility counteract these advantages.
Checkpointing in streaming applications, is the process of tracking which messages have been successfully read from the stream
Checkpointing can help with system disruptions, but the frequency with which you checkpoint must be carefully considered.Frequent checkpoints result in faster recovery but lower performance.
3. Lambda Architectures
Definition from wiki :)
Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch and stream-processing methods. This approach to architecture attempts to balance latency, throughput, and fault-tolerance by using batch processing to provide comprehensive and accurate views of batch data, while simultaneously using real-time stream processing to provide views of online data. The two view outputs may be joined before presentation. The rise of lambda architecture is correlated with the growth of big data, real-time analytics, and the drive to mitigate the latencies of map-reduce
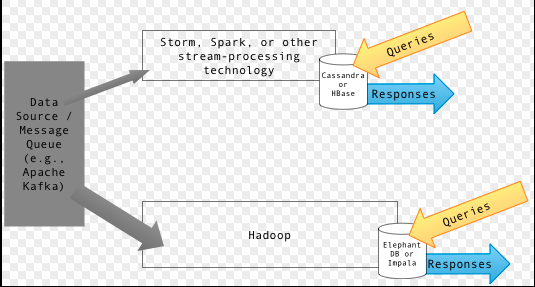
Bringing the goodness/durable approach of batch processing and mixing it up with fast stream processing.
Side Kick: Comes with a operational complexity !!!
Good Reads:
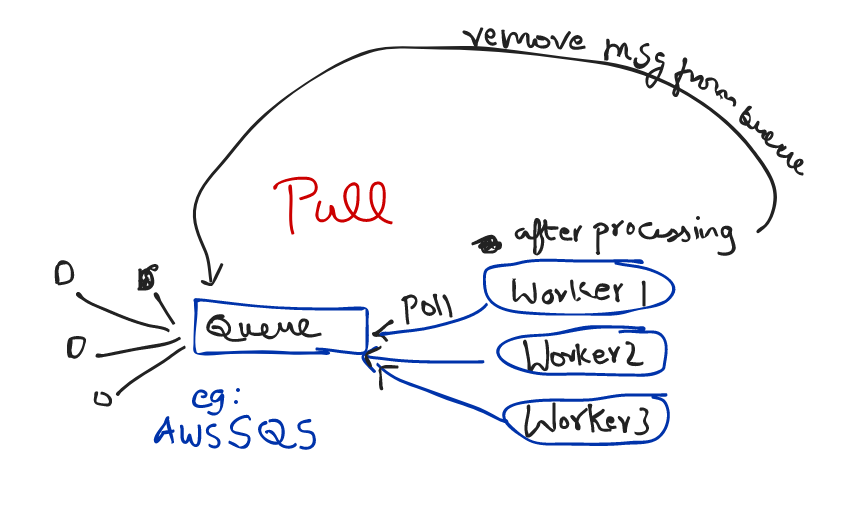
4. Queues
We just saw about streaming where that large data flowing through a stream,may have complexity associated with them since there is no "persistence" i.e no storage
Queues make the async process more "reliable" and less fragile since events are captured and processed in a order.
Task queues are a type of message queue, sometimes they're built on top of message queues. For example, Celery supports many different "message brokers", such as Redis, RabbitMQ, and Amazon SQS.
Message Queues and Task Queues
- Message queues, which receive, log, and deliver messages, can be used to update users that jobs are being processed in the background, thus unblocking them and making for a better user experience. SQS, Redis and RabbitMQ are popular choices.
Good Reads: AWS SQS
- Task queues execute in addition to passing information. They schedule jobs, complete tasks, and report results. Celery is a popular choice.
Good Reads: Introduction to Asynchronous Task Queueing Celery
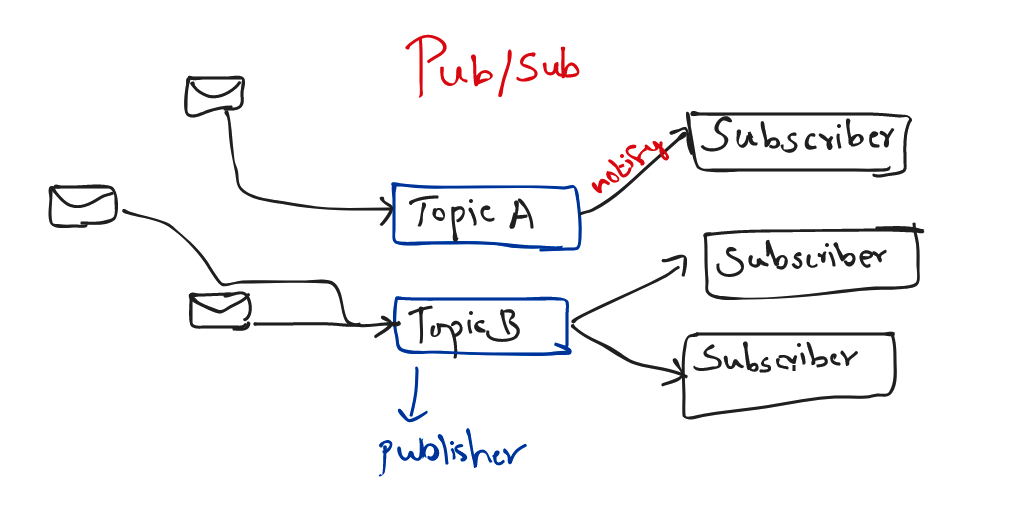
Publish/Subscribe (or pub/sub)
Messaging is another async communication method to know. In pub/sub messaging, you have a subscriber who receives a message sent by a publisher via a broker. Because communication is decoupled, messages can be automatically pushed to all subscribers rather than pulled individually via a message queue. This method is popular in event-driven architecture because event-driven services can be delivered quickly and easily. Additionally, because publishers are isolated from subscribers, the system is easier to maintain and secure.
eg: SNS
See yourself Situations:
Consider using asynchronous processing when
You think processing time is now known or takes longer
It can wait to be processed
Batch processing is useful when you need to process chunks of data in predictable intervals, as in accounting software. Stream processing is a good choice for applications like anomaly detection or sentiment analysis when timeliness is critical, and lambda architecture can help you capture the benefits of both if you're willing to deal with added complexity. Synchronous processing is still the best choice for simple applications where processing times are short and well-defined, and when errors must be dealt with immediately like in payment tools.
Some more
News Feeds - Pub/Sub ( subscribe for a news letter and you'll get it for sure)
Web Crawling - Batch Processing, Map Reduce
Analytics - Batch Processing, Map Reduce
Handling real time events - Streams Processing
Large File Uploads - Jobs Queue
Scheduled tasks - Jobs queue, Batch processing




