#13 System Design: Consistent Hashing

Backend Developer and a busy mom who loves technology and sharing knowledge that makes her fulfilling and happy
Hola !! Welcome back to the 13th episode. If you have been following along in the system design series, we spoke about consistent hashing when we learnt about caching. Let's learn what hashing and hash tables are before diving into consistent hashing.
What is hashing?
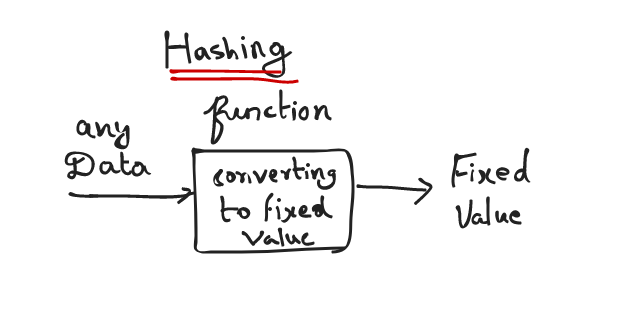
A hash function is any function that can be used to map data of any size to fixed-size values. The values returned by the hash functions are called hash values or hash codes or digests or simply hashes. The values are usually used to index a fixed size table called a hash table
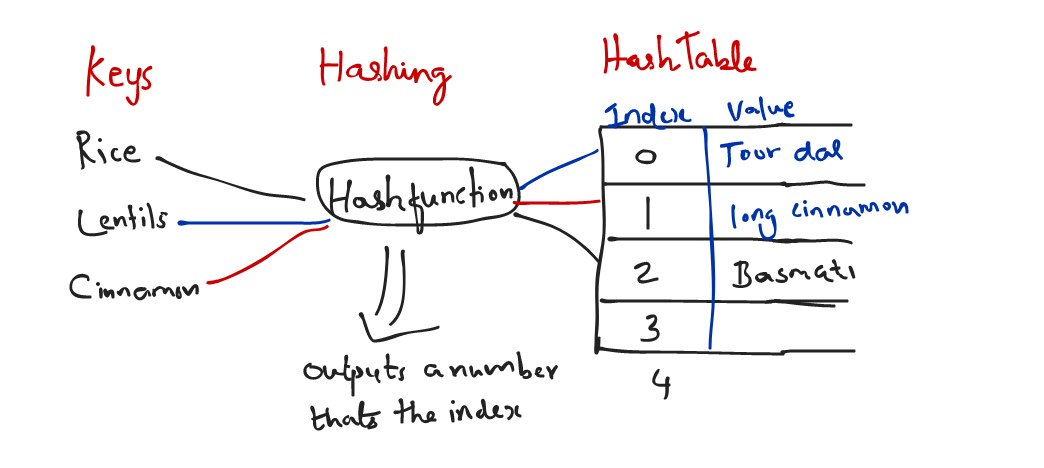
What is Hashtable?
Imagine you are buying a lot of lentils, rice, spices from the grocery shop and would like to organize them in your pantry. You would put them as you see below in the mason jars(assume these jars are not see through) and label them with their names so that its easier. That's usual process.
Assume, we want to use these jars in future to rotate for other spices without peeling/changing the label off. How would we do it ! One way is to label it with numbers.

We have a smart label maker that can generate a number label for us if we say the name of the ingredient. It internally stores the mapping of the number with their names. we will put the label on the jars now.
So anytime you buy more of these groceries ( so that you don't run of stock) you'll have tell the label maker the name of the ingredient, and it will tell you the number. if it does exist already in its mapping it would tell you the number to look for, and you can go find that jar and put more of the ingredient inside it. If its a brand new ingredient then the label maker is going to generate a new number label for it and give you one.
This is the craziest way of navigating a pantry ! But you get the idea.
If you don't want to open each of the jars yourself to check what ingredient it has when you want to restock more (remember they are not see through jars). You basically want to speed the searching process by talking to a label maker that hashes the names of the ingredients.
Keys >> The label numbers
Values >> the actual stored ingredient
Hash Table >> Smart Label Maker has it.
So in programming world, if we wanted to speed the search of finding a item by its key we can store the key value pair or just the key and value can be anything you want.
What is the algorithm of this Hash Function?
Well it can be anything ! Let's look at a real use case now.
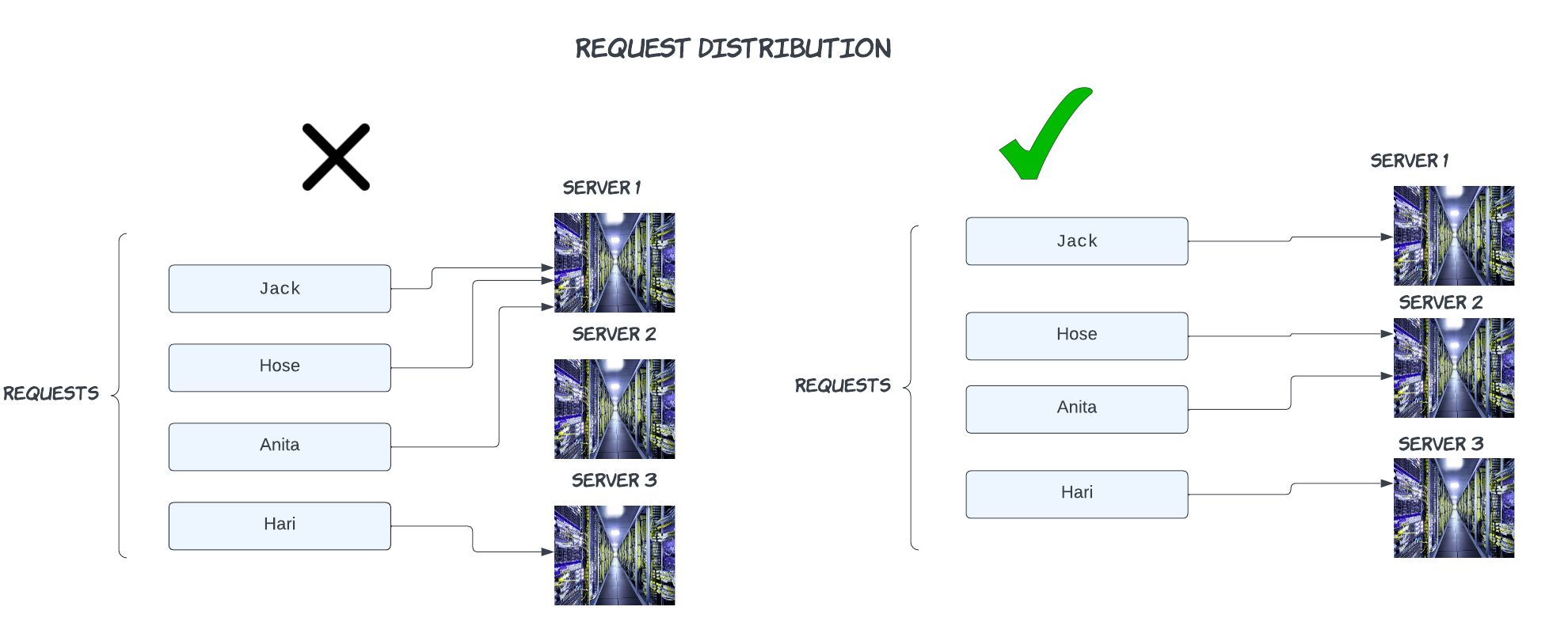
We have a client request who needs to find an item from the cache, since its a distributed environment there are many cache servers and we need a mechanism to tell which server the request should go to, we don't want to burden any specific cache server, also we want to make sure that the load is evenly spread at any given point of time.
Distributed systems are expected to be reliable and available, correct? This means that it has to withstand variations in traffic and be able to function even if there is a network failure.
Let's see traditional hashing
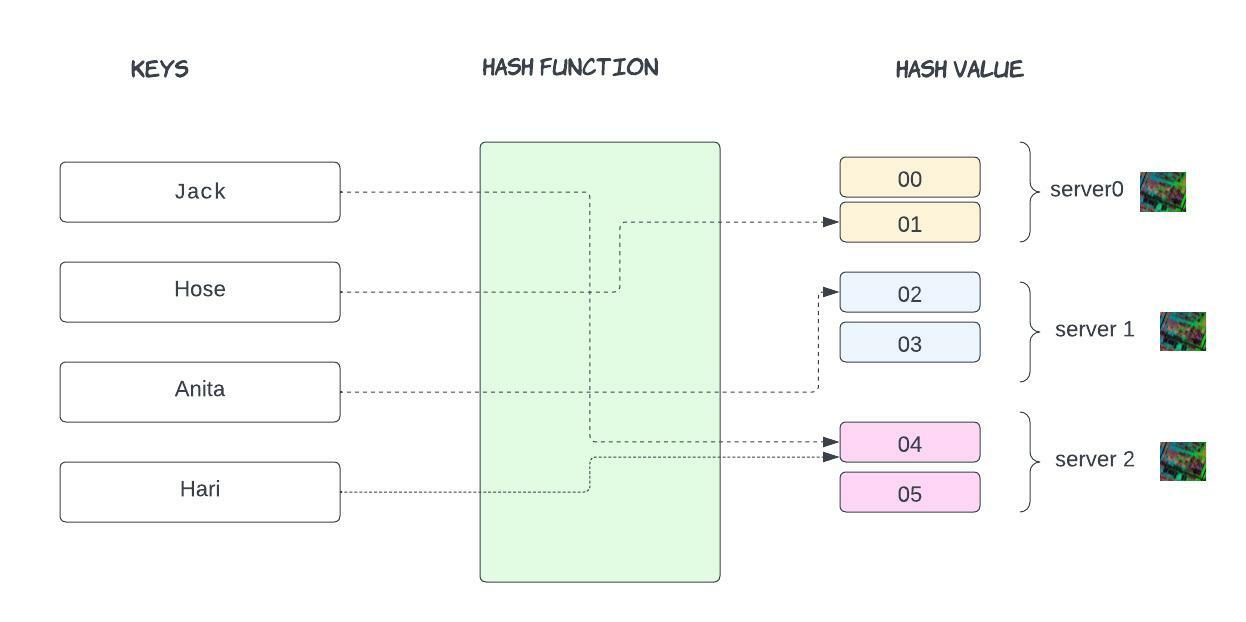
Jack - 04
Hose - 01
Anita - 02
Hari - 04
In this example, hash values range from 00-05. Conventional methods for distributing data among caches take the serverKey = (hash_function(key) % N) to determine which of the servers' keys will ultimately be mapped.
Note that N, the number of servers in the network(we have three servers), is part of the mapping. Because of this, N must stay stable or every key-value pair will need to be remapped.
We can see in the standard case where the number of servers is the expected number N, then the mapping is straightforward.
The reality is that when nework failures happen we would have to add or remove servers which changes the N( the number of servers on the network) and all the keys would have to remapped now !!!!!
Say for instance server2 fails. N (total servers) becomes 2
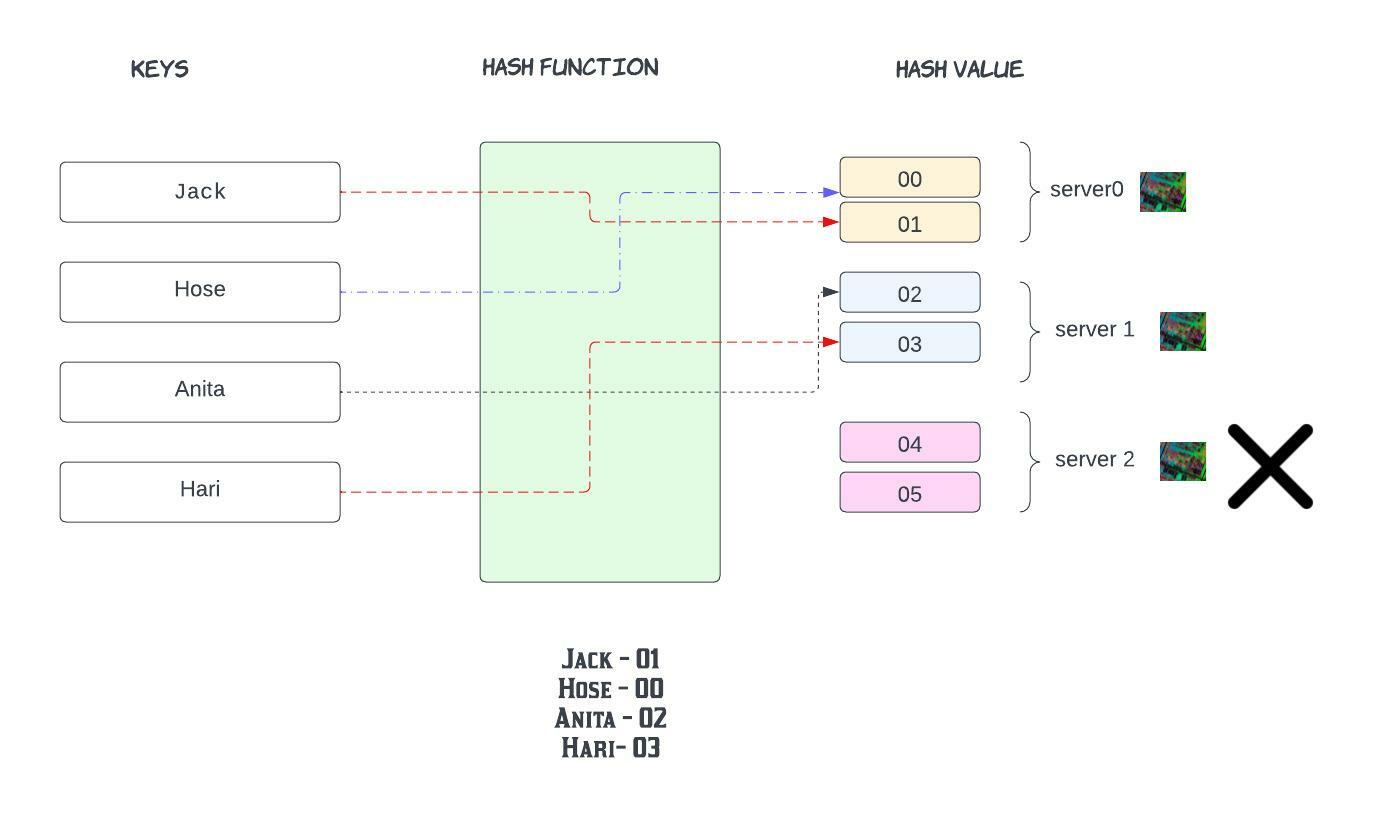
Previous:
Jack - 04
Hose - 01
Anita - 02
Hari - 04
Now: Except, Hose everyone got re-distributed !!!
What happens if we wanted to add one more server??

Almost all keys will have to be remapped to different servers
A serious question to ask is whether there is a more efficient solution for distributing data across servers? or Is there some way where only have to remap a small number of servers when we add or remove servers?
Tadaaa that brings us to the topic of !!!!
Consistent Hashing:
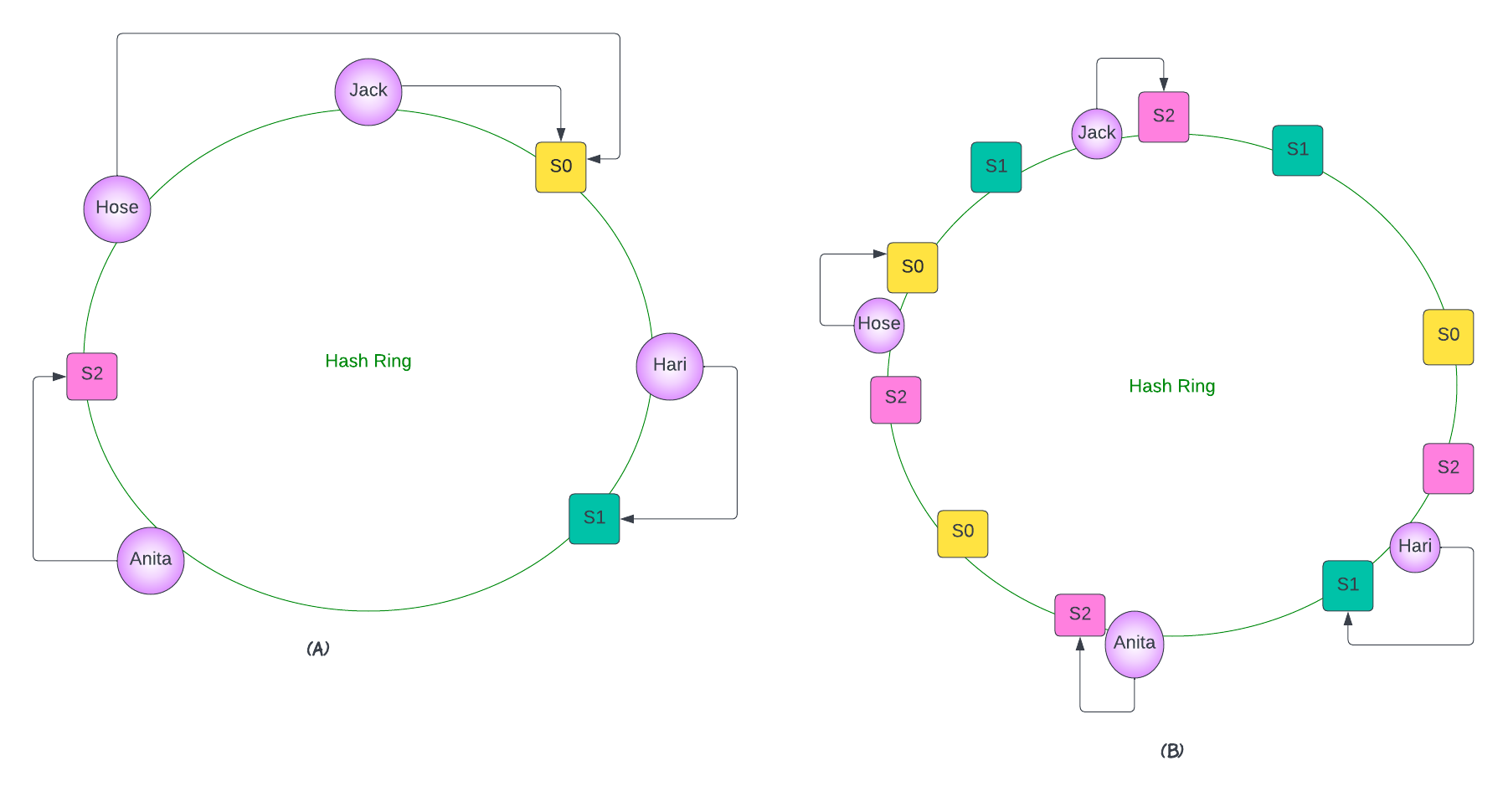
Part A
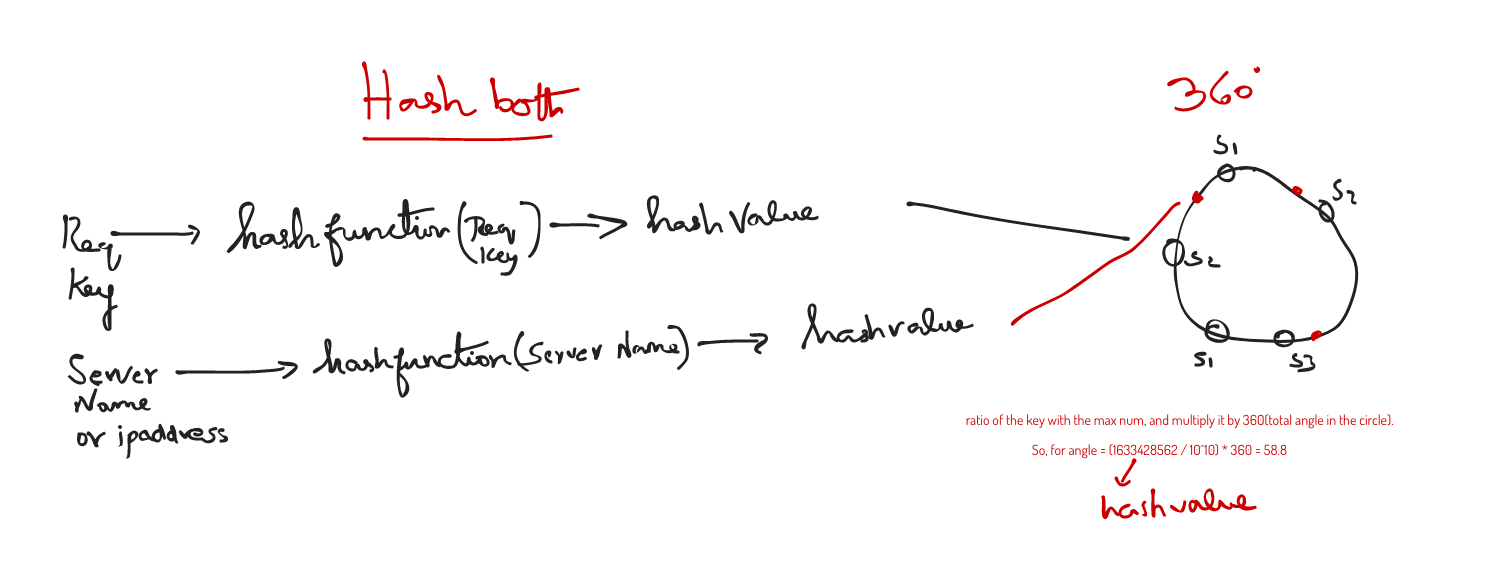
Consistent hashing was an great solution to solving the limitations of more conventional hashing methods. It was introduced so that the remapping of key-value pairs to servers is consistent, even when servers are added or removed. In this method, servers and objects are mapped to positions on what is termed a hash circle. Let us suppose we have 3 servers and 4 keys. We can map each of these to a value on the circle using the hash function and then use a linear mapping to map the hash values to a value between 0 and 2π.
Part B - Add more servers now and distribute the load
Now, we can assign objects to servers. For instance, one convention that works well is assigning the key to its closest server in the clockwise direction. To improve the computational efficiency of the algorithm and to guarantee a more even distribution of load across servers, multiple requests are associated with each one of the servers.
server 0 is mapped 3 times on the hash circle, as are server 1 and server 2. Note, different weightings can be assigned to the server—which will produce a different desired load distribution across the servers. In this way, less keys will have to be remapped when servers are added or removed.
Let's imagine server 1 fails. Note that none of the keys have to be rehashed. Instead, all the servers mapped on the circle associated with server 1 are removed. In this case, the key may be reassigned to a different server (since the closest one in the clockwise direction may no longer be server 1).
The pros of this approach is that:
- Not all keys have to be reassigned to different servers.
- The hash value of the keys do not need to be recomputed.
Let's see the failure situation in the diagram
Hari was server by S1 and now he would move to S2 (clockwise closest)
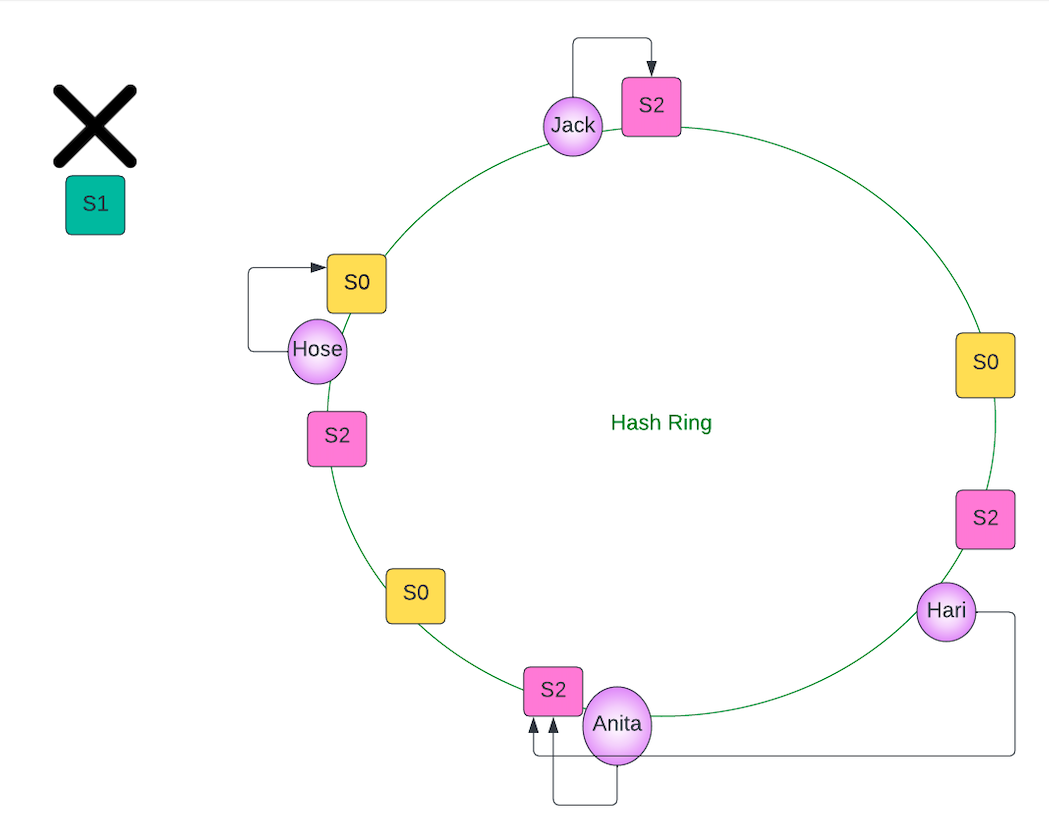
Therefore, we can see the advantages that consistent hashing offers over traditional hashing methods! In real life, caching systems like Memcached and Redis, support out-of-the-box solutions for consistent hashing.
Summary:
Consistent hashing is a mechanism for storing data (keys and objects) across several servers that is consistently. It outperforms traditional hashing methods in terms of adapting to the addition or removal of servers in the ecosystem.
Good Reads: Facebook Engineering blog
Happy Learning :)



