



Welcome to the 14th episode :)
What is Reliability?
Reliability and Availability has always been the major focus in distributed systems. The ability of the cloud provider to provide highly available and reliable services is the key for customer success.
Designing and building for reliability means, accounting for security, error handling, disaster recovery and number of other contingencies.
Why Account for Failures?
Because things are bound to go wrong.
Any system with dependencies must have logic to deal with failures, whether due to network outages, hardware failure, a sloppy roll-out, or a malicious attack. The majority of distributed system failures are caused by one of two factors.
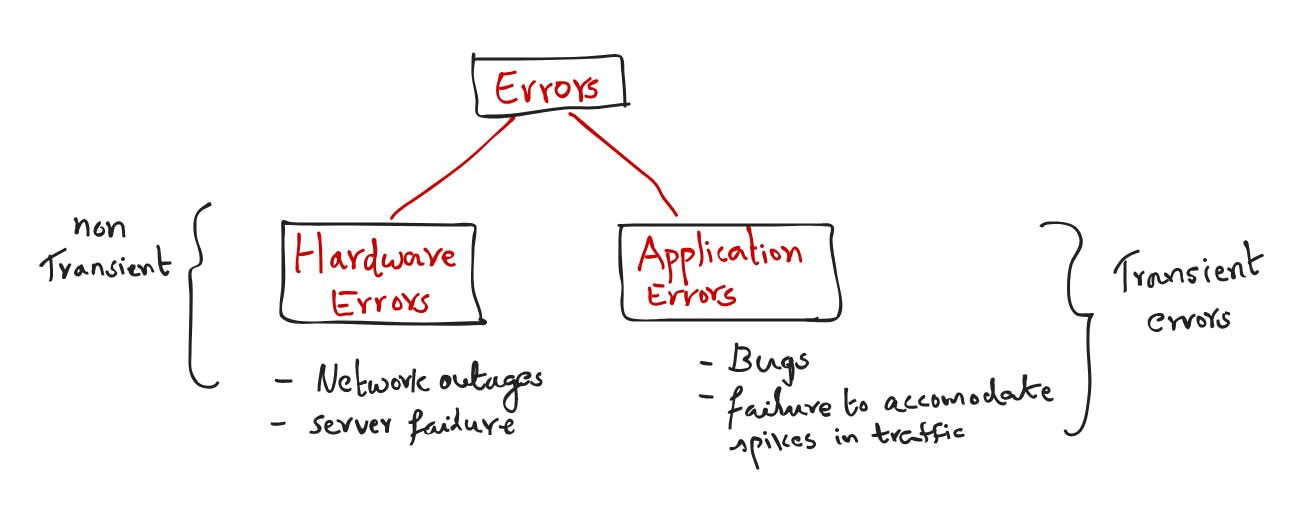
Increasing system reliability should obviously have ramifications for performance and cost in terms of complexity, engineering effort, and money.
Retries
Simple retry strategy:
When the failure occurs in any part of a system, the application that detected that failure will simply retry until it can successfully connect. But if we know that the failure is going to be present for sometime e.g like network failures repeatedly retrying may overload the downstream system once the network issue is resolved.
Well you know its down, why simply keep bothering it !!!
Delayed retry is a mechanism adopted to retry after a set amount of time allowing the system/component under failure to recover.
So if the set time is hard coded/fixed to be say 5 mins or 5hours, is that reasonable? Is there a better way to retry?? !
That's exactly what an "exponential backoff" strategy does. It is an algorithm that uses a pre-defined process to gradually, multiplicatively decrease the rate of an operation to find a more acceptable rate.
i.e The wait time is increased exponentially after every attempt
What if "Exponential backoff" leads to very long backoff times, because exponential functions grow quickly !!!
To avoid retrying for too long, implementations typically cap their backoff to a maximum value. This is called, predictably, capped exponential backoff
Ok ! the system/component is not up yet. Now all the applications are retrying at the capped max value rate. At some point the clients are going to give up anyways because they have their own timeouts.
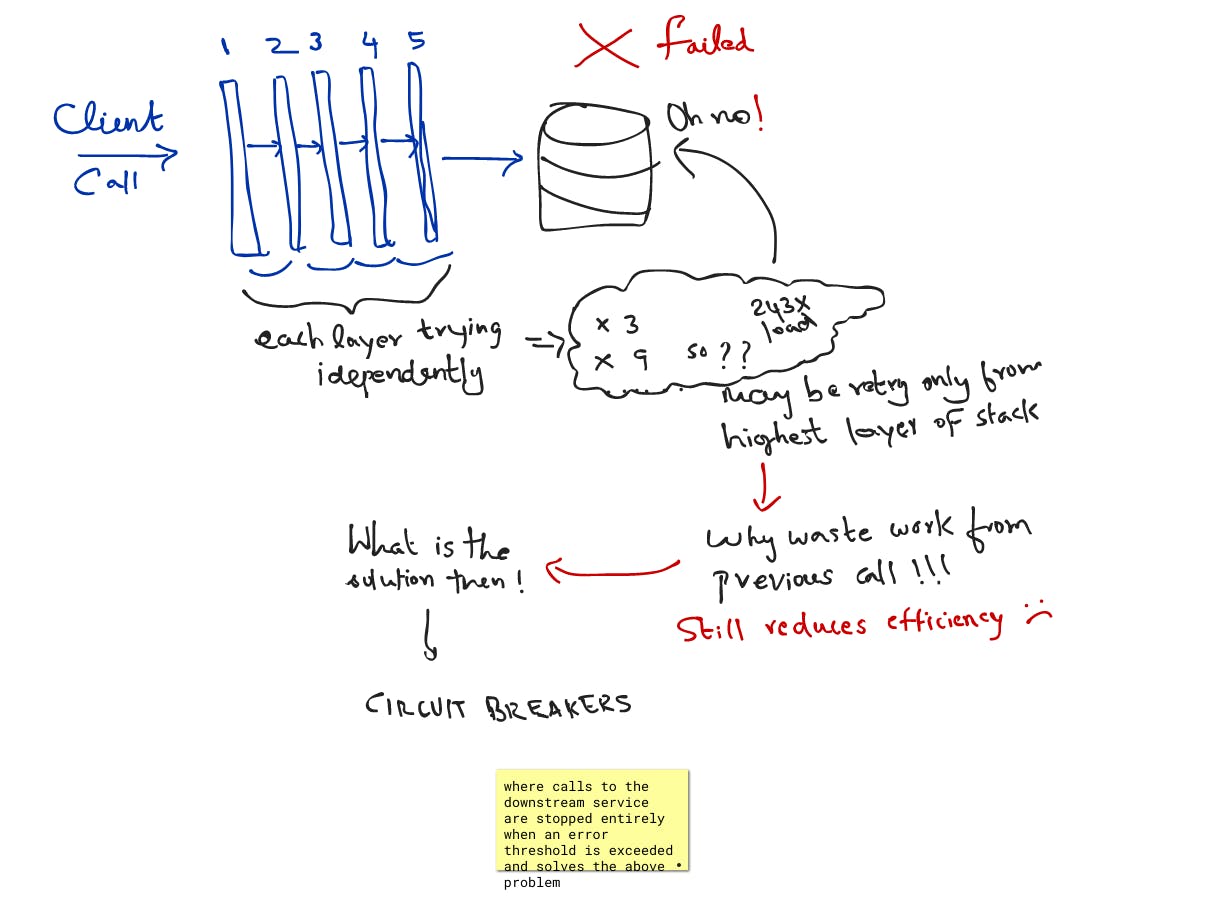
In general, for low-cost control-plane and data-plane operations, our best practice is to retry at a single point in the stack. Even with a single layer of retries, traffic still significantly increases when errors start. Circuit breakers, where calls to a downstream service are stopped entirely when an error threshold is exceeded, are widely promoted to solve this problem.
The above understanding was derived from the below article Very Good Read >> Timeouts and Retries
Techniques and considerations

Once the error is rectified, retry accumulation in high-traffic systems might result in extraordinarily high system load. This is known as the thundering herd problem, and it can cause much more issues than the transitory error because your resource(s) are unable to cope with the high volume of requests.
To prevent client requests from synchronizing, introduce jitter, or "randomness," to the delay intervals.
Keep in mind that, from a user experience standpoint, it's sometimes preferable to fail quickly and just inform users.
Implement a low retry limit in this scenario and notify users that they will need to try again later.
Circuit Breakers

How does a circuit break work in real life?
When physical circuit breakers detect that an electrical system isn't working properly, they turn off the electricity. After the circuit has been rectified, simply flip the switch to restore electricity. Similarly, a circuit breaker method works. When the breaker identifies a problem, it suspends requests until the issue is resolved.
All is working well and the circuit breaker is in a closed state. It monitors the number of recent failures, and if this number exceeds a threshold within a given interval, the circuit breaker is set to open. No further requests are let through. A timer is set, giving the system time to fix the issue without receiving new requests. Once the timer expires, the circuit breaker is set to half-open.
A few requests are allowed through to test the system. If all are successful, the breaker reverts to its closed state and the failure counter is reset. If any requests fail, the breaker reverts to open and the timer starts again.
Circuit Breaker States
- Closed
- Open
- Half-Open
Closed When everything is normal, the circuit breaker remains in the closed state and all calls pass through to the services. When the number of failures exceeds a predetermined threshold the breaker trips, and it goes into the Open state. Open The circuit breaker returns an error for calls without executing the function. Half-Open After a timeout period, the circuit switches to a half-open state to test if the underlying problem still exists. If a single call fails in this half-open state, the breaker is once again tripped. If it succeeds, the circuit breaker resets back to the normal, closed state.
Good Read: Circuit Breaker Pattern
Pros
- Prevents cascading failures when a shared resource goes down.
- Allows for a fast response in cases where performance and response time are critical (by immediately rejecting operations that are likely to timeout or fail).
- Circuit breakers' failure counters combined with event logs contain valuable data that can be used to identify failure-prone resources.
Techniques & considerations
There are a few main points to remember when implementing circuit breakers.
You'll need to address exceptions raised when a resource protected with a circuit breaker is unavailable. Common solutions are to temporarily switch to more basic functionality, try a different data source, or to alert the user.
Configure the circuit breaker in a way 1) the patterns of recovery you expect 2) your performance and response time requirements. It can be difficult to set the timer accurately. It may take some trial and error.
Saga

Saga is a microservice architecture method that requires successfully completing a set of local transactions across numerous independent services in order to complete an action (also known as a distributed transaction).
What if you have a setback in the middle of the project? This type of failure might completely destabilize your system.
Assume you're the owner of an ecommerce site. When a customer purchases an item, the item is added to their cart, their payment is processed, and the item is fetched from inventory, shipped, and invoiced. If you don't pull the item from inventory, you'll have to reverse the charge to your customer - but now you're trapped because you don't have any structured "compensating transactions" in place to reverse the successful transactions.
A saga is a story with a different structure. The component local transactions are decoupled, grouped, and executed sequentially instead of as a single distributed transaction. A saga is a collection of related local transactions.When your saga coordinator (more on that later) identifies a failure, it activates a set of "countermeasures," effectively undoing the previous activities.The inventory number would revert to its prior condition on our ecommerce site, and payment and cart adjustments would be reversed.
To implement a saga strategy, you can either coordinate saga participants via choreography, a decentralized approach where each local transaction triggers others, or orchestration, where a centralized controller directs saga participants.
Very Good Read: Saga Pattern
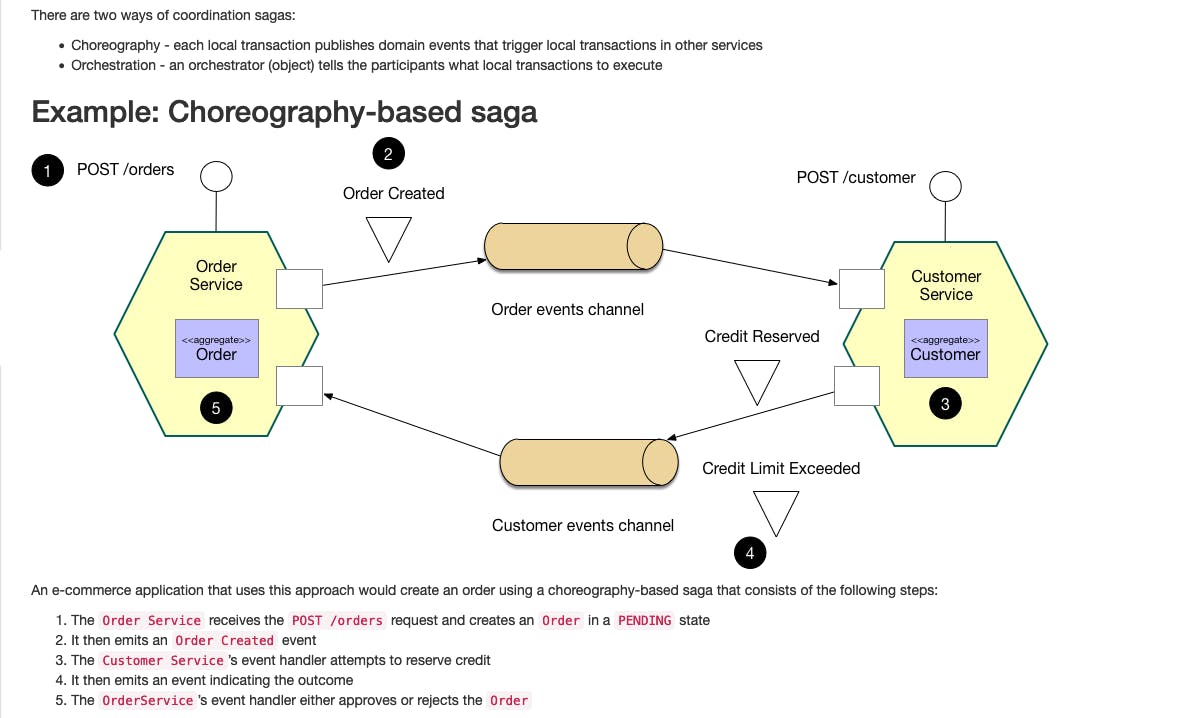
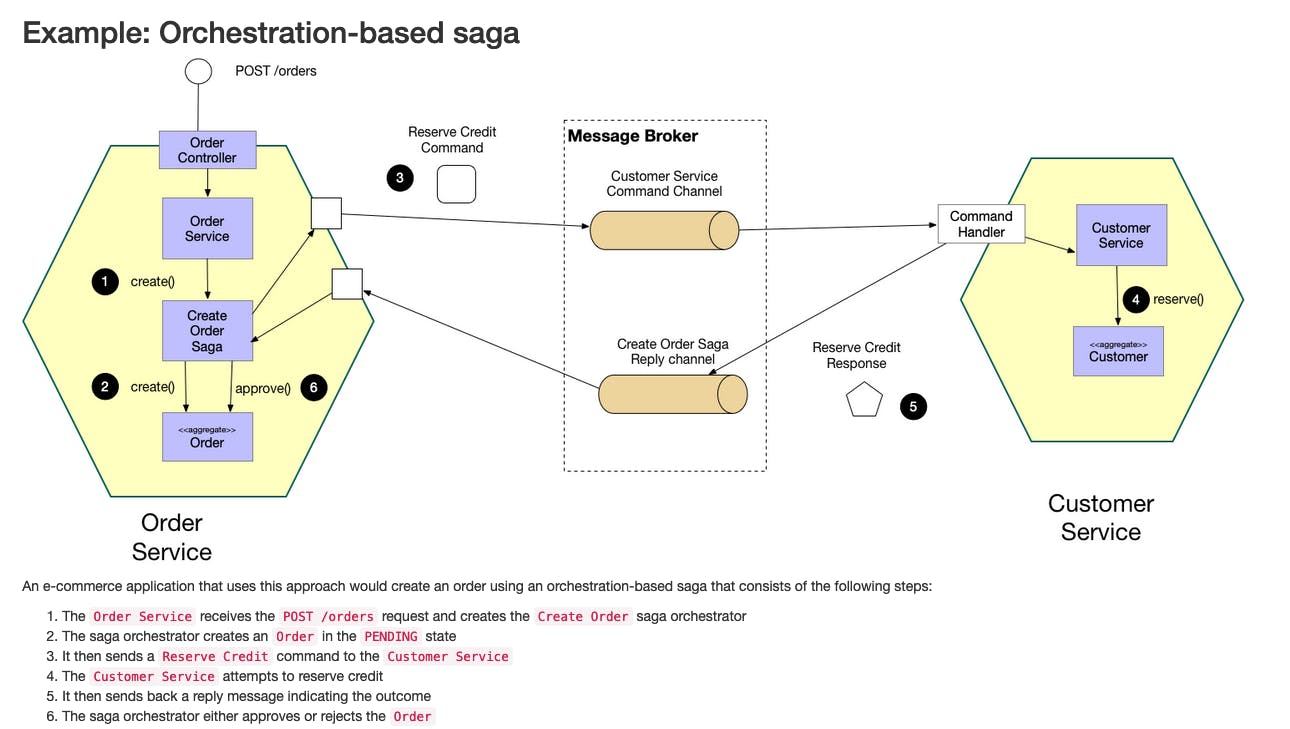
Use cases
- Maintains data consistency across multiple services.
- Well-suited to any microservice application where idempotency (the ability to apply the same operation multiple times without changing the result beyond the first try) is important, like when charging credit cards.
- For microservices in which there aren't many participants or the set of counter transactions required is discrete and small consider choreographed saga as there's no single point of failure.
- For more complex microservices, consider orchestrated saga.
Techniques & considerations
Sagas can add a great deal of complexity to your system. You'll need to create a series of compensating transactions that will be triggered by various failures. Depending on your application, this could necessitate a significant amount of work up front to analyze user behavior and possible failure modes.
Now you know how reliable systems are built :)
Happy Learning :)