



High availability (HA) can be achieved when systems are equipped to operate continuously without failure for a long duration of time.
Availability is typically expressed as a percentage of uptime / total time. Although it's difficult to ensure 100 percent availability, most cloud providers include a high availability guarantee in their service level agreements, which is close to the coveted 'five nines,' or 99.999 percent availability (SLAs.)
Let's see some of the strategies involved
Rate Limiting:
The term "rate limiting" refers to a limit on the number of times an operation can take place in a certain time frame. The fundamental reason for rate limitation is to safeguard your service against overuse, whether intentional or not.
"How can rate-limiting requests enhance availability if we're dropping requests?"
It's vital to emphasize that you aren't turning down all requests, good or bad. You're simply limiting the amount of data that users, organizations, IP addresses, and other elements of your system can access.
On both the client and server sides, rate limitations can be imposed. This will reduce latency, increase throughput, and assist control traffic while avoiding unnecessary costs.
Managing and monitoring API throttling in your workloads Rate Limiting Strategies for Serverless Applications
Scenarios:
Avoid going over budget with an autoscaling component.
In the event of a DoS attack or inadvertent usage, maintain the availability of a public API.
Assist SaaS providers in controlling access and cost per customer.
Techniques Used in Rate Limiting:
Token Bucket Algorithm:
A token bucket strategy recognizes that not every request necessitates the same amount of "effort." In order to fulfill a request, the service seeks to withdraw a specified number of tokens. Numerous tokens may be "costed" by a request requiring multiple processes. The service has reached its maximum capacity if the bucket is empty. Tokens are restored at a set rate, allowing the service to regain its feet.
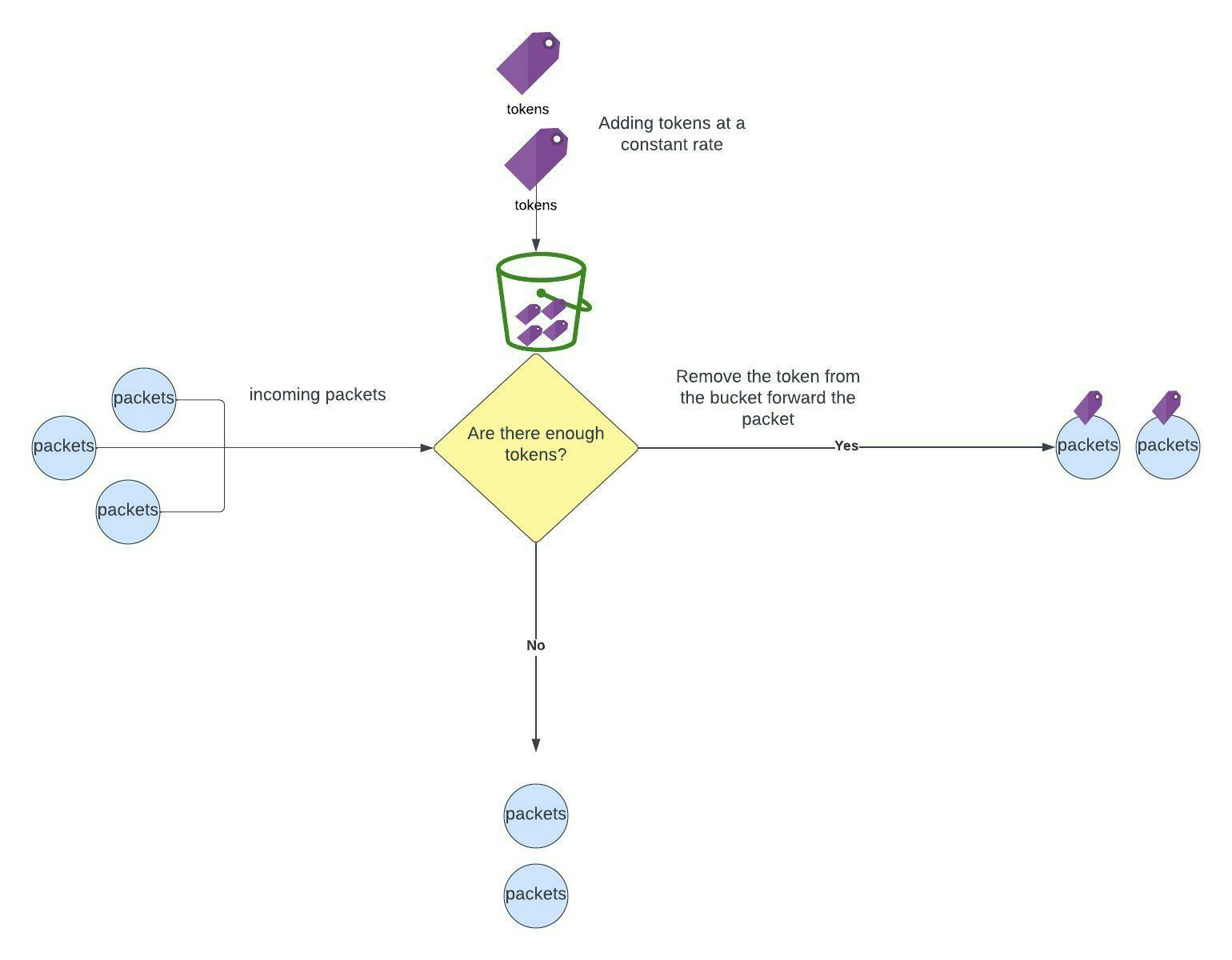
This is like using your money wisely as you build wealth, the more commitments to spend money, closer you get to eventually run out !
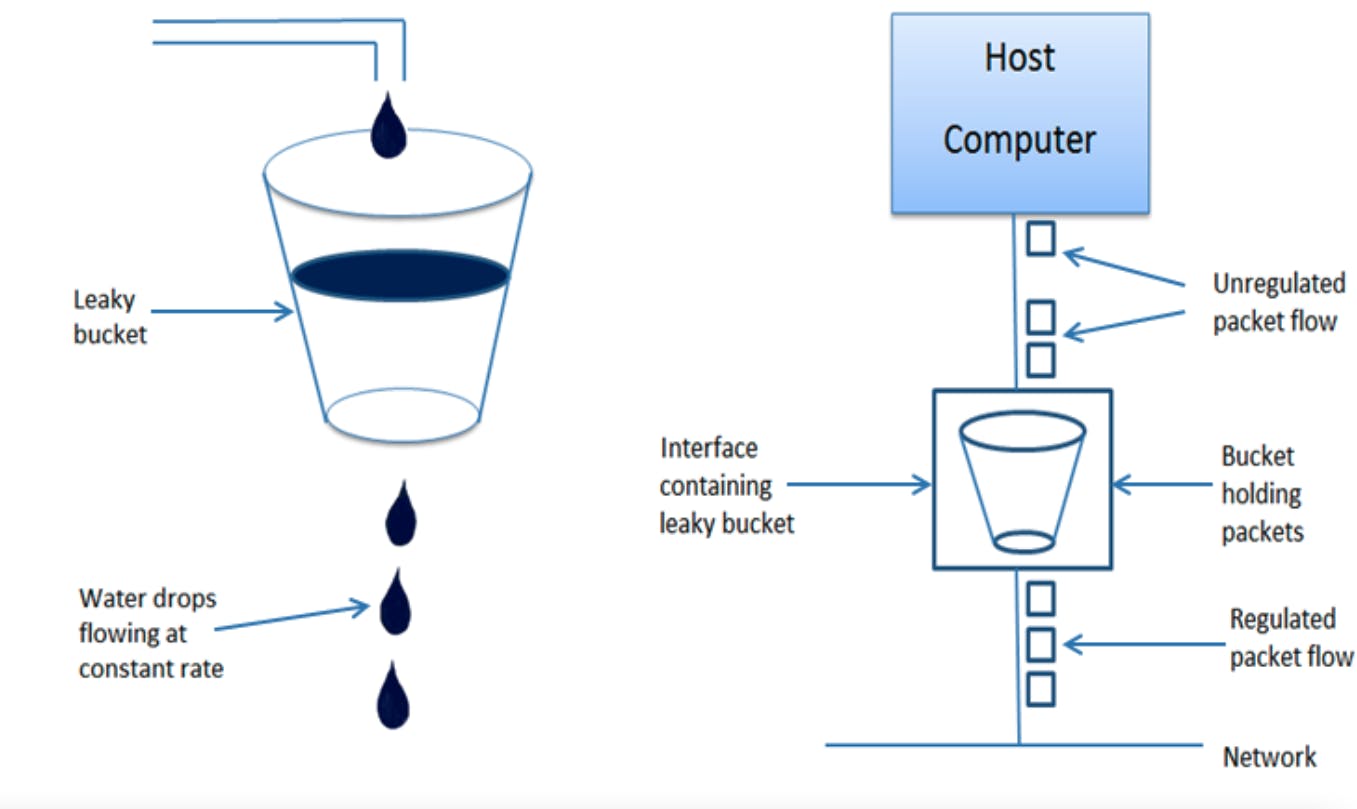
Leaky Bucket Algorithm:
A leaking bucket has a similar effect.Requests are collected and stored in a bucket. Each additional request adds to the growing weight of the bucket. New requests are discarded or leaked when the bucket is full (and the limit has been reached).
Steps:
- When host wants to send packet, packet is thrown into the bucket.
- The bucket leaks at a constant rate, meaning the network interface transmits packets at a constant rate.
- Bursty traffic is converted to a uniform traffic by the leaky bucket.
- In practice the bucket is a finite queue that outputs at a finite rate.
Fixed and sliding window:
Fixed window rate limiting is simplicity itself - for example, 1000 requests per 15-minute window. Spikes are possible, as there's no rule preventing all 1000 requests from coming in within the same 30 seconds. Sliding window "smooths" the interval. Instead of 1000 requests every 15 minutes, you might define a rule such as 15 requests within the last 30 seconds.
Rate limiting using the Fixed Window algorithm
Queue-Based Load Leveling
Well we don't like the idea of dropping these requests, I'm okay with a queue that will collect all the requests and store them so that the service can receive them in a orderly fashion
That's exactly what Queue Based load leveling is all about !
The ideal real-world analog for queue-based load leveling is a drive-through. You wouldn't try to serve 1000 people at the same time if you were a restaurant owner. Cars are instead channeled through a FIFO (first-in-first-out) queue.
Scenarios where it's used
- Susceptible to overloading
- Higher latency is acceptable during spikes, and
- It's important that requests are processed in order.
this strategy assumes it's easy to decouple tasks from services. Consider the queue depth, message size and rate of response.
Gateway Aggregation
Another option for dealing with complex requests or reducing "communications" between the client and the backend service is to put a gateway in front of the backend service. Before collecting results and sending them back to the client, the gateway aggregates requests and dispatches them appropriately.
Scenarios where it's used
Reduce cross-service "communications," particularly in microservice design, where operations necessitate coordination between numerous small services.
Reduce latency (if your service is complex and users already rely on high latency networks like mobile.)
API Gateway / Backends for Frontends
Considerations:
Gateways are straightforward, but if yours isn't well-designed, you've created a possible point of failure. Make sure your gateway can handle the expected traffic and expand with you. Make use of reliable design strategies such as circuit breakers or retries, and load test the gateway. If it has several duties, you may want to put an aggregation service in front of it to free it up so it can focus on its other tasks and route requests appropriately and fast.
Zoo Keeper:
The out of the box approach for achieving high availability is "Zoo Keeper".
ZooKeeper is a distributed, open-source coordination service for distributed applications. It exposes a simple set of primitives that distributed applications can build upon to implement higher level services for synchronization, configuration maintenance, and groups and naming. It is designed to be easy to program to, and uses a data model styled after the familiar directory tree structure of file systems. It runs in Java and has bindings for both Java and C.
Coordination services are notoriously hard to get right. They are especially prone to errors such as race conditions and deadlock. The motivation behind ZooKeeper is to relieve distributed applications the responsibility of implementing coordination services from scratch.
That's what I got for "High Availability"
Happy Learning :)