#6 System Design: Caching Strategies

Backend Developer and a busy mom who loves technology and sharing knowledge that makes her fulfilling and happy
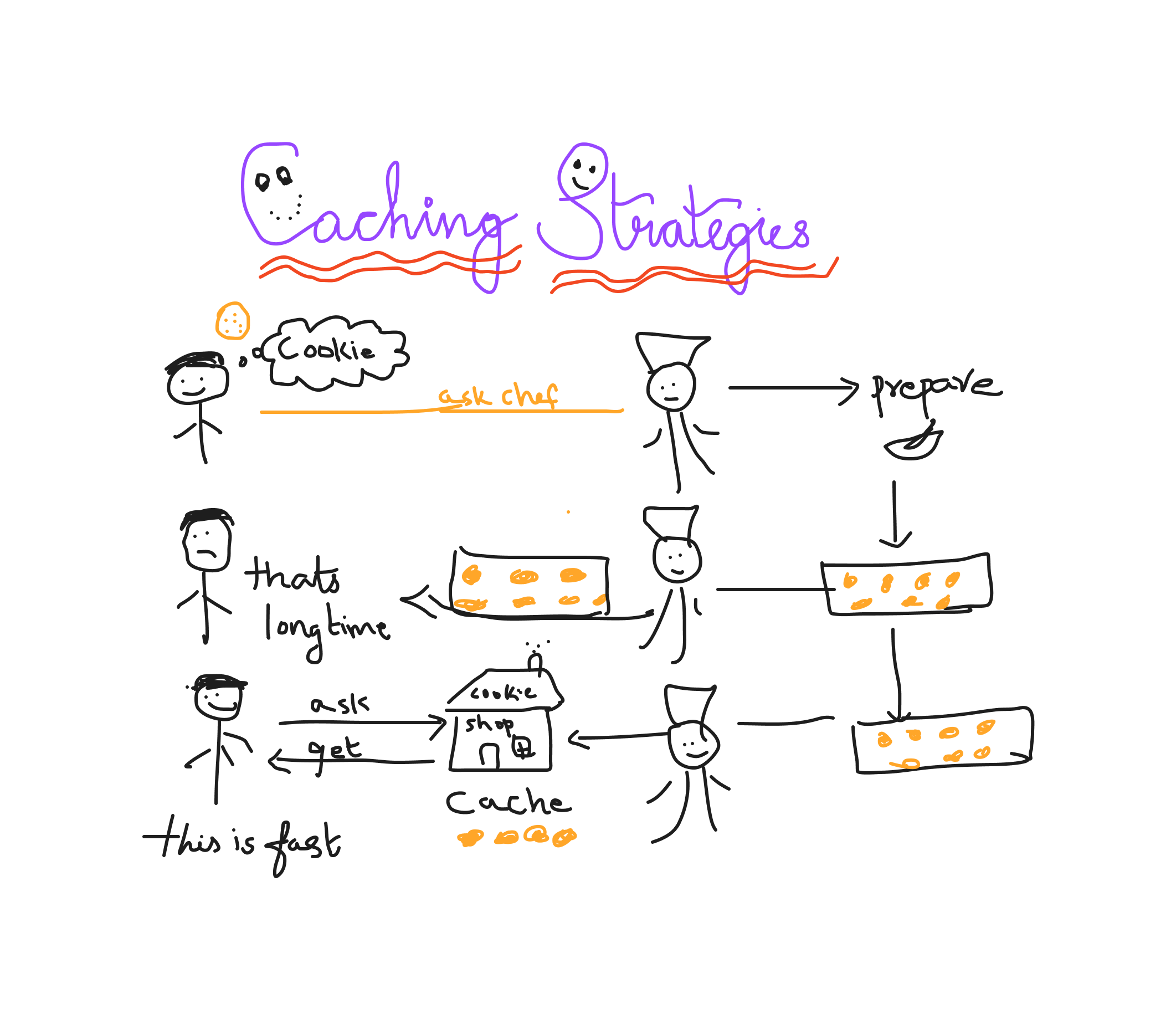
Welcome to the 6th Series..
Serving yourself on weekdays, by prepping on weekends, could save you time getting the vegetables cut, mixed, cooked, and finally served.
What if I said "This sort of "Caching" in real life" :) Ha ha !!
Caching Defined
Its a storage technique that's omnipresent in computer systems and it plays a very important role in designing scalable applications.
A cache is any data store that can store and retrieve data quickly, enabling faster response times thereby decreasing load on other parts of your system.
Why do I have to know?
Computers and the Internet would be incredibly slow without caching due to the time it takes to get data at each stage.
Caches use the locality principle to store data closer to where it is most likely to be needed.
Even within your computer, this principle is at work !! as you browse the web, your web browser caches images and data on your hard drive; data from your hard drive gets cached in memory, and so on.
Caching can also make data retrieval more efficient in large-scale Internet applications by avoiding repeated calculations, database queries, or calls to other services. This frees up resources that might be put to better use in other areas, such as serving more traffic.
Caching can also refer to the storing of pre-computed data that would be difficult to offer on demand(similar to store selling a cookie that's already made)
Some examples of caching are news feeds, reports etc etc
Knowing when to cache and when not to is very important !!
How Caching Works
Caching can be implemented in many different ways in modern systems:
In-memory application cache:
Storing data in the application's memory is a quick and easy alternative, but each server must maintain its own cache, increasing the system's overall memory requirements and cost.
Distributed in-memory cache:
A separate caching server such as Memcached or Redis can be used to store data so that multiple servers can read and write from the same cache.
Database Cache:
A conventional database can still be used to cache frequently accessed data or to save the results of pre-calculated processes for later retrieval. In fact, the cloud offerings like Redis use databases for caching behind the scenes.
File system cache:
A file system can also be used to store commonly accessed files
CDNs are one example of a distributed file system that take advantage of geographic locality.
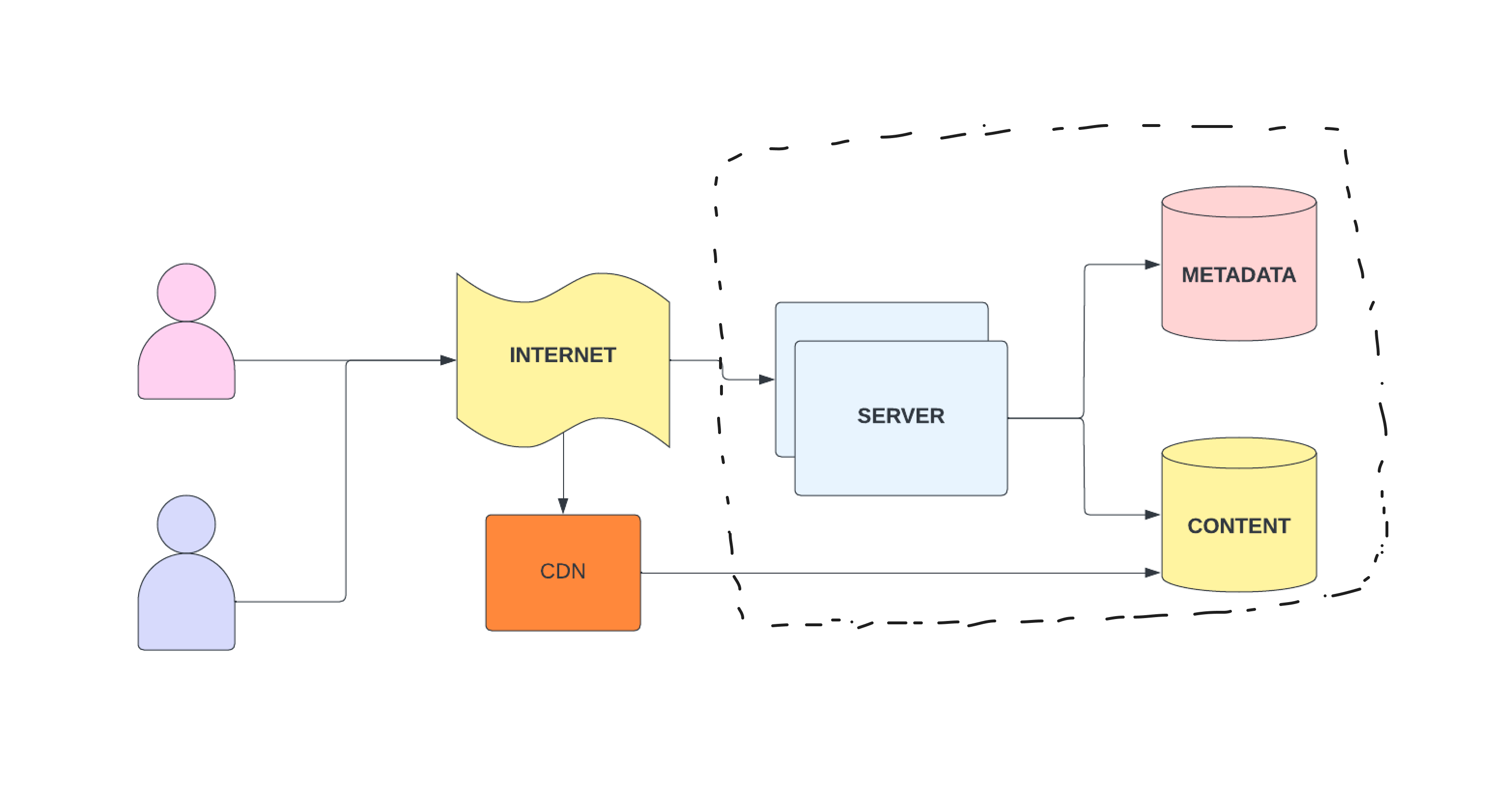
Eg: AWS Cloud Front
Caching Policies
If caching is so great, why not cache everything?
There are two main reasons: cost and accuracy.
Caching is generally implemented with more expensive and less resilient hardware than other types of storage because it is supposed to be rapid and transient. As a result, caches are often smaller than primary data storage systems, and they must choose carefully which data to store and which to discard (or evict). This selection procedure, referred to as a caching policy, aids the cache in freeing up space for the most important material that will be required in the future.
Here are some common examples of caching policies:
First-in first-out (FIFO)
Similar to a queue, this policy evicts whichever item was added longest ago and keeps the most recently added items.
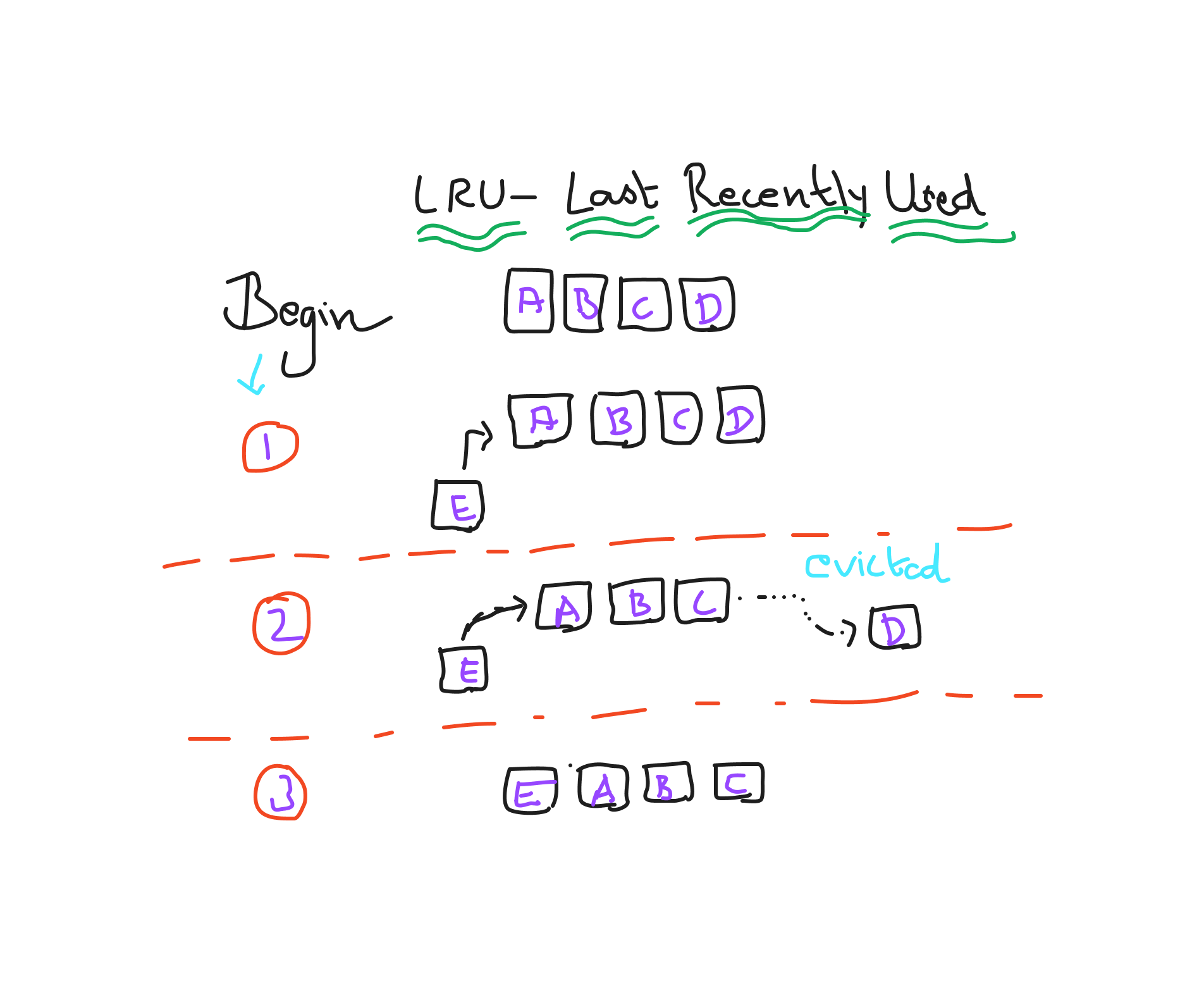
Least recently used (LRU):
This policy keeps track of when items were last retrieved and evicts whichever item has not been accessed recently.
Least frequently used (LFU):
This policy keeps track of how often items are retrieved and evicts whichever item is used least frequently, regardless of when it was last accessed. It's similar to LRU, except that it also remembers how many times it was used.Therefore, in the case of CDN, LFU becomes highly effective as it keeps track of frequency as well.
In addition, caches can quickly become out-of-date from the true state of the system. This speed/accuracy tradeoff can be reduced by implementing an eviction policy - most commonly by limiting the time-to-live (TTL) of each cache entry, and updating the cache entry before or after database writes (write-through vs. write-behind).
Cache Coherence
How to ensure cache consistency given our requirements ?
A write-through cache updates the cache and main memory simultaneously, meaning there's no chance either can go out of data. It also simplifies the system.
In a write-behind cache, memory updates occur asynchronously. This may lead to inconsistency, but it speeds things up significantly.
Cache-aside or lazy loading where data is loaded into the cache on-demand. First, the application checks the cache for requested data. If it's not there (also called a "cache miss") the application fetches the data from the data store and updates the cache. If it already has the data its called "cache hit" and the data is returned from cache quickly.
This simple strategy keeps the data stored in the cache relatively "relevant" - as long as you choose a cache eviction policy and limited TTL combination that matches data access patterns.

Considerations
How big?
Consider how latency minimization would affect your users vs. the additional cost of more complexity and expensive equipment at a high level. After that, think about the anticipated request volume as well as the size and distribution of cached objects. After that, create your cache in such a way that it satisfies your cache hit rate goals.
Eviction?
This will be determined by your application, however LRU is by far the most popular. It's simple to set up and works well in most situations.
Expiration?
Setting an absolute TTL based on data usage trends is a common and straightforward solution.
Consider how stale data affects your users and how frequently data changes.
You're not going to get it right the first time.




