#9 System Design: Sharding

Backend Developer and a busy mom who loves technology and sharing knowledge that makes her fulfilling and happy
Welcome to the 9th episode :)
Hey ! I want to store the data of how many of my house devices are connected to the network and their utilization metrics on a database.
Here you go take it !
Now I have to do it for my entire community !! They love the mobile app I made
Oops!!! I now have to store data for all the people out in the world.
Even a database that big with expensive hardware is still not enough to deal with the above situation. We have already scaled vertically and have hit the limits. What do we do now?
The only option we have is to scale horizontally!
What I mean by that is, split our database and place them across multiple separate database servers. This process of breaking up large tables into horizontal data partitions, each of which contains a subset of the whole table, and putting each partition on a separate database server is called sharding, and each partition is called a shard.
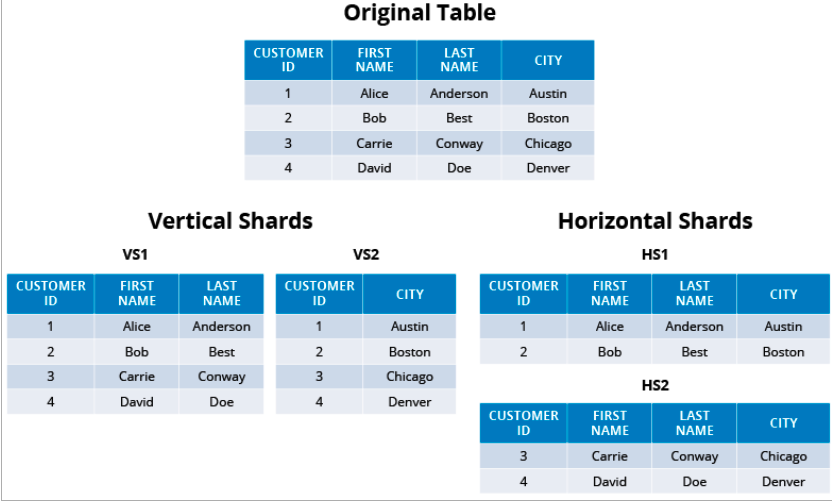
Vertical Partitioning:
When you split the table's columns across partitions, in this case the customerId, firstName and lastName resides on a VS1 shard and customerId and city is stored by the VS2 shard. This is called vertical partitioning.
When a user request comes in to search the city that the user belongs to, it will be routed to VS2 and can be processed faster to return the response. Since that is now separate shard and there is less data to deal, it eases the time to respond thereby increasing the overall performance.
Horizontal Partitioning:
Splitting the rows of data and keeping them in separate partitions is called horizontal partitioning.
As you see above Alice and Bob are in HS1, Carrie and David are in HS2.
Sharding Vs Partitioning
Sharding and partitioning are both about breaking up a large data set into smaller subsets. The difference is that sharding implies the data is spread across multiple computers while partitioning does not.
Now that the data resides in multiple shards, how do I know where to go( which shard to go to) to query and get my results?
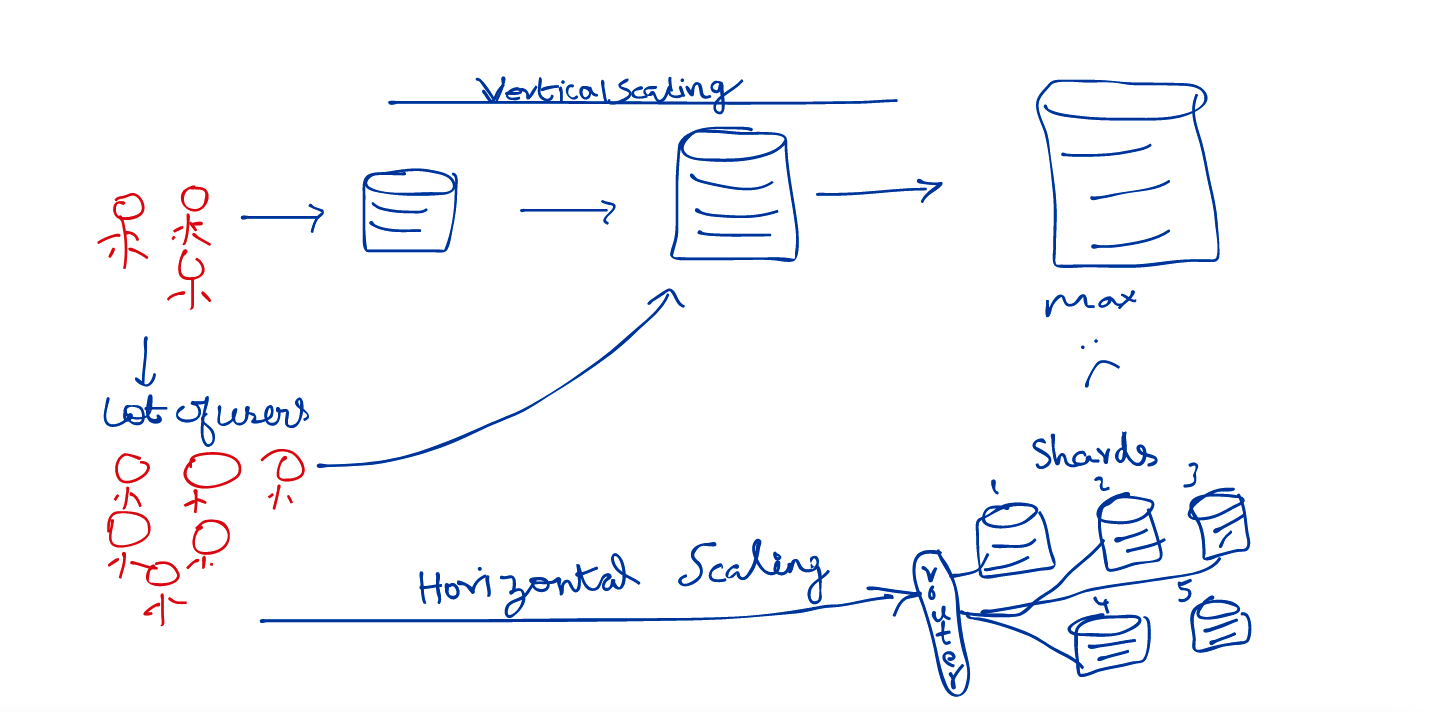
There are actually lot ways you can get to the server that you need to talk to depending on your use case.
Sharding techniques
Most times, the technique used to partition data will depend on the structure of the data itself. A few common sharding techniques are:
Geo-based sharding
Data is partitioned based on the user’s location, such as the continent of origin, or a similarly large area (e.g. “East US”, “West US”). Typically, a static location is chosen, such as the user’s location when their account was created.
This technique allows users to be routed to the node closest to their location, thus reducing latency. However, there may not be an even distribution of users in the various geographical areas.
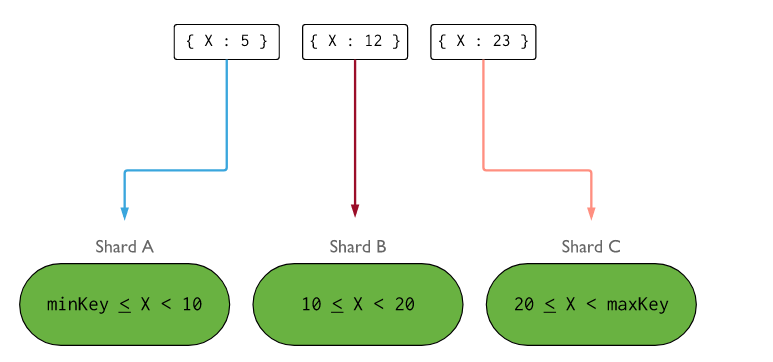
Range-based sharding
Range-based sharding divides the data based on the ranges of the key value. For example, choosing the first letter of the user’s first name as the shard key will divide the data into 26 buckets (assuming English names). This makes partition computation very simple, but can lead to uneven splits across data partitions.
Another example is when the shard key is the user's age then range can be used..
Hash-based
This is popular technique that uses a hashing algorithm to generate a hash based on the key value, and then uses the hash value to compute the partition. A good hash algorithm will distribute data evenly across partitions, thus reducing the risk of hot spots. However, it is likely to assign related rows to different partitions, so the server can’t enhance performance by trying to predict and pre-load future queries.
Logical Vs Physical Shards:
Grouping the logical shards and placing them on a physical database server(Physical Shard)
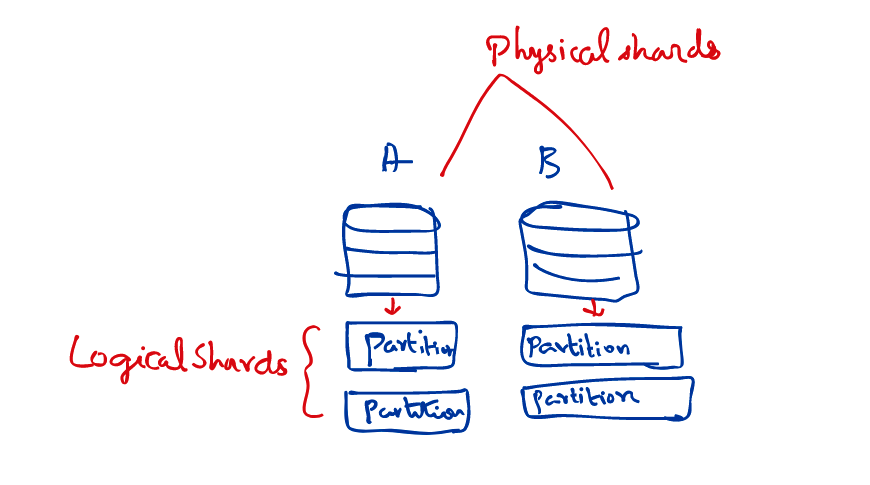
A and B are physical shards
The partitions that belong to each of them is called Logical shard
Advantages of Sharding :)
Let's say we have a table that stores data about "Produce" and their availability by region in a single table. Now, we have schemas split as logical shards and assigned to their own database servers based on their geographical location.
When the user wants to query the "Produce" data by a location eg: Baltimore, the query will be routed to the server that's in Baltimore to get the data to the user quickly.
Having a smaller set of data in each shard also means that the indexes on that data are smaller, which results in faster query performance.
that's great & loved performance for sure !!
If an unplanned outage takes down a shard, the majority of the system remains accessible while that shard is restored. Downtime doesn’t take out the whole system.
Since there is more than one database server, its highly available too!
Smaller amounts of data in each shard mean that the nodes can run on commodity hardware, and do not require expensive high-end hardware to deliver acceptable performance.
Disadvantages
- Not all data can be sharded. Infact sharding is chosen after trying all other things
like query optimization, adding read replicas.
Foreign key relationships can only be maintained within a single shard.
Manual sharding can be very complex and can lead to hots pots.
eg: If you designed such that group A users reached S1 and group B users always reached S2 and if the group B users decided to create more data, causing load/stress on S2, that's a hot spot.
The only way to solve hot spots is to reshard.
Because each shard runs on a separate database server, some types of cross-shard queries (such as table joins) are either very expensive or not possible.
Once sharding has been set up, it is very hard (if not impossible) on some systems to undo sharding or to change the shard key.

Each shard is a live production database server, so needs to ensure high-availability (via replication or other techniques). This increases the operational cost compared to a single RDBMS.
Manual Vs Dynamic/Automatic Sharding:
Dynamic sharding is a feature of some database systems that allows the system to manage data partitioning.When automatic sharding finds an uneven distribution of data (or queries) among the shards, it will automatically re-partition the data, resulting in improved performance and scalability.
Many monolithic databases, unfortunately, do not support automated sharding.
If you need to keep using these databases but your data demands are growing, sharding at the application layer is required.However, there are several substantial drawbacks to this.
One disadvantage is that the development process becomes much more difficult.
The application must select the proper sharding mechanism and determine the number of shards based on expected data patterns.If the application's underlying assumptions change, it must rebalance the data partitions.The application must determine which shard the data is stored on and how to access it during runtime.
Another challenge with manual sharding is that it typically results in an uneven distribution of data among the shards, especially as data trends differ from what they were when the sharding technique was chosen.
Hotspots created due to this uneven distribution can lead to performance issues and server crashes.
If the number of shards chosen initially is too low, re-sharding will be required in order to address performance regression as data increases.
This can be a significantly complex operation, especially if the system needs to have no downtime.
Operational processes, such as changes to the database schema, also become rather complex. If schema changes are not backward compatible, the system will need to ensure that all shards have the same schema copy and the data is migrated from the old schema to the new one correctly on all shards.
Good Reads
Happy Learning :)




